貪吃蛇 RL 進化史:從人工智障到禪意大師的辛酸血淚
2026年1月18日 · wemee
在將強化學習 (Reinforcement Learning) 應用到貪吃蛇這個經典遊戲時,我們最初以為這會是一場輕鬆的勝利。畢竟,規則如此簡單:吃蘋果,變長,不要撞牆。
但我們錯了。錯得離譜。
這篇文章記錄了我們過去 48 小時的掙扎、失敗,以及最終那個令人驚嘆的「頓悟時刻」。
第一章:溫室裡的花朵 (The Loop of Despair)
為了讓 AI 快速學會吃蘋果,我們一開始設計了非常「貼心」的獎勵機制:
- 靠近蘋果:給你糖吃 (+0.05)。
- 遠離蘋果:打你手心 (-0.1)。
- 時間懲罰:每走一步扣分 (模擬飢餓)。
我們以為這樣能引導它快速找到目標。結果,我們創造了一個不願冒險的懦夫。
當蘋果出現在角落,或者被身體稍微擋住時,AI 發現:「天啊,要吃到那個蘋果,我必須先遠離它(繞路)。但遠離它會被扣分!救命!」
於是,它做出了最理性的選擇:在原地轉圈圈。 因為轉圈圈只會被扣一點點飢餓分,而去繞路會被扣「遠離蘋果」的大分。它選擇了慢性死亡,也不願冒險去贏。這就是 RL 領域經典的 Local Optima (局部最優陷阱)。
第二章:嚴刑峻法 (Strict Rules)
為了制止它轉圈圈,我們惱羞成怒,引入了更嚴格的規則:
- 禁止重複路徑:如果你敢走回剛才走過的位置,直接判死刑!
- 空間感知 (Flood Fill):如果你的車頭朝向一個封閉空間,直接判死刑!
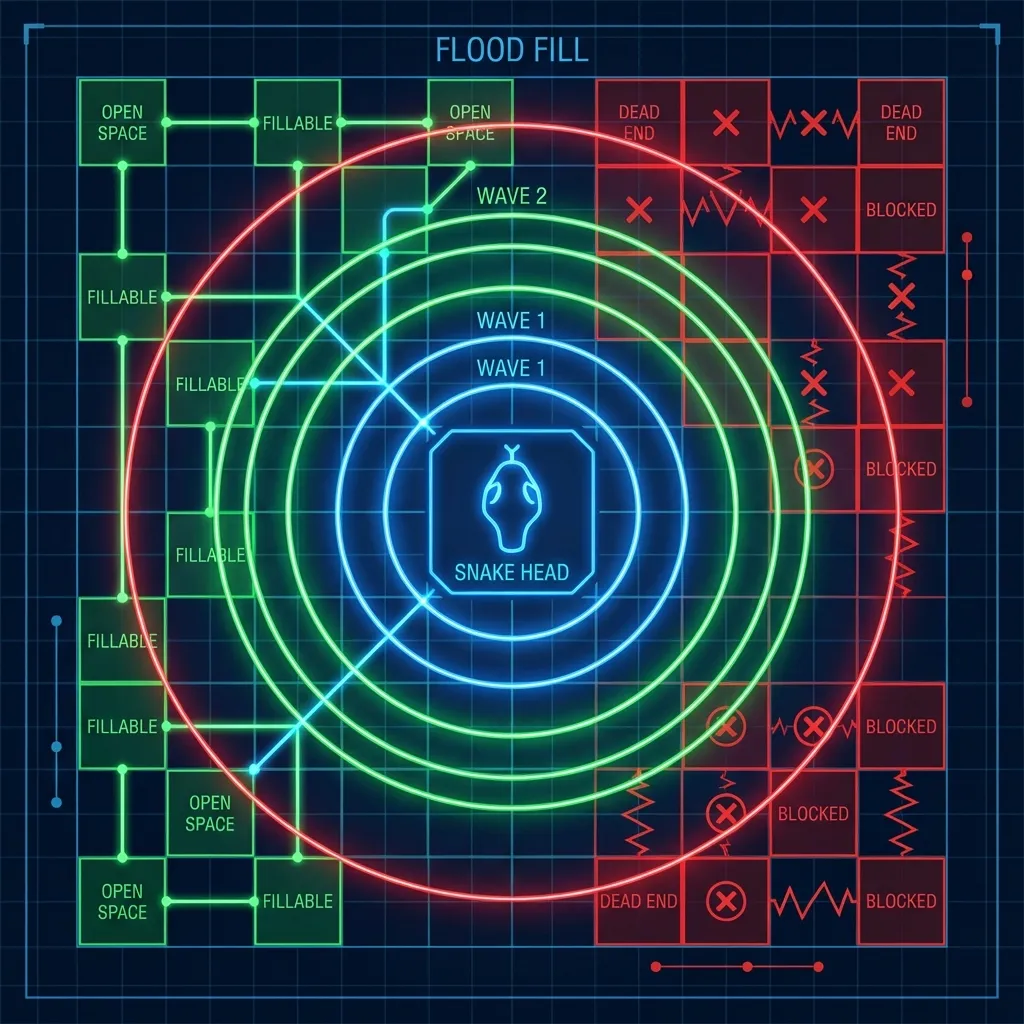
這看起來很科學,對吧?我們用 Flood Fill 算法預判死路,給它安裝了最強的「雷達」。
結果呢?AI 變成了神經質的潔癖患者。 它變得極度害怕貼牆走,因為貼牆很容易觸發「封閉空間預警」。原本它可以鑽進一個 S 型縫隙吃蘋果再鑽出來,現在它只要看到縫隙就掉頭跑走。
分數雖然略有提升,但它看起來不像條蛇,像個受驚的掃地機器人。
第三章:頓悟 (The Zen Moment)
在無數次調整參數、修改獎勵函數卻只能在這個泥淖中打轉後,我們終於意識到:問題不在於我們給的獎勵不夠好,而在於我們給得太多了。
我們就像那些過度干涉孩子的父母,幫它規劃了每一步的「好壞」,卻剝奪了它自己探索「長期策略」的機會。
於是,我們做了一個大膽的決定:刪除所有規則。
- ❌ 移除「靠近蘋果」獎勵。
- ❌ 移除「遠離蘋果」懲罰。
- ❌ 移除「空間感知」懲罰。
- ❌ 移除「飢餓」累積扣分。
我們只留下最純粹的真理:
- 吃到蘋果:+10 分 (這是唯一的目標)。
- 撞牆/撞自己:-10 分 (這是唯一的禁忌)。
- 每步成本:-0.001 分 (只是為了讓你不要睡著)。
- 超時限制:給它 500 步的寬裕時間,而不是用飢餓逼它。
這就是 Pure Survival Mode。我們把一條白紙般的蛇丟進了殘酷的 10x10 競技場,告訴它:「活下去,想辦法吃。」
第四章:大師誕生 (The Master)
訓練剛開始,分數暴跌。因為沒有了「指南針」(距離獎勵),它像個無頭蒼蠅一樣亂撞。
但到了 10 萬步的時候,奇蹟發生了。
因爲不再害怕「遠離蘋果」會被扣分,它開始學會繞路。 因為不再有「飢餓累積」的壓力,它開始學會等待。 它會優雅地繞到地圖最外圈,把身體排成整齊的 S 型,然後從容地滑進去吃掉那顆被包圍的蘋果,再毫髮無傷地滑出來。
最終成績:
- 平均長度:從 15 提升到 28.3。
- 最高紀錄:單局吃掉 41 顆蘋果 (佔地圖 40% 面積)。
- 行為模式:不再急躁,充滿禪意。它學會了犧牲眼前的微小利益(走遠路),換取生存的空間。
結語:AI 教會我們的事
這場實驗給了我們一個深刻的教訓:In RL (and life), sometimes less is more.
當我們停止微操 (Micromanagement),停止告訴 AI「怎麼做」,而是只告訴它「目標是什麼」時,它展現出了超越我們設計的智慧。
現在的這條蛇,不再是為了分數而跑,它是為了生存而跑。 請到我們的 Snake AI Demo 親自體驗這條禪意之蛇的優雅吧。