瀏覽器裡的 AI:如何實現 Python 訓練、JS 推理的低耦合架構
2026年1月18日 · wemee
在將強化學習 (Reinforcement Learning) 應用到網頁遊戲時,開發者常面臨一個兩難:
- 在瀏覽器訓練 (TF.js):整合容易,但訓練速度極慢,缺乏成熟的 RL 算法庫。
- 在 Python 訓練:生態系強大 (Torch, Gymnasium),但部署到網頁需要架設後端 API,延遲高且成本貴。
這次在開發 Snake AI 時,我們設計了一套 「Python 訓練 + TypeScript 推理」 的低耦合架構,成功實現了兩全其美:在 Python 中利用 GPU 快速訓練,導出極輕量的權重 (JSON),在前端瀏覽器進行零延遲推理。
更重要的是,我們利用 策略模式 (Strategy Pattern) 解決了特徵提取 (Feature Extraction) 的耦合問題,讓我們能隨時切換 AI 的「視野」而不影響核心邏輯。
架構概覽
整體架構分為兩個獨立但透過協議連接的世界:
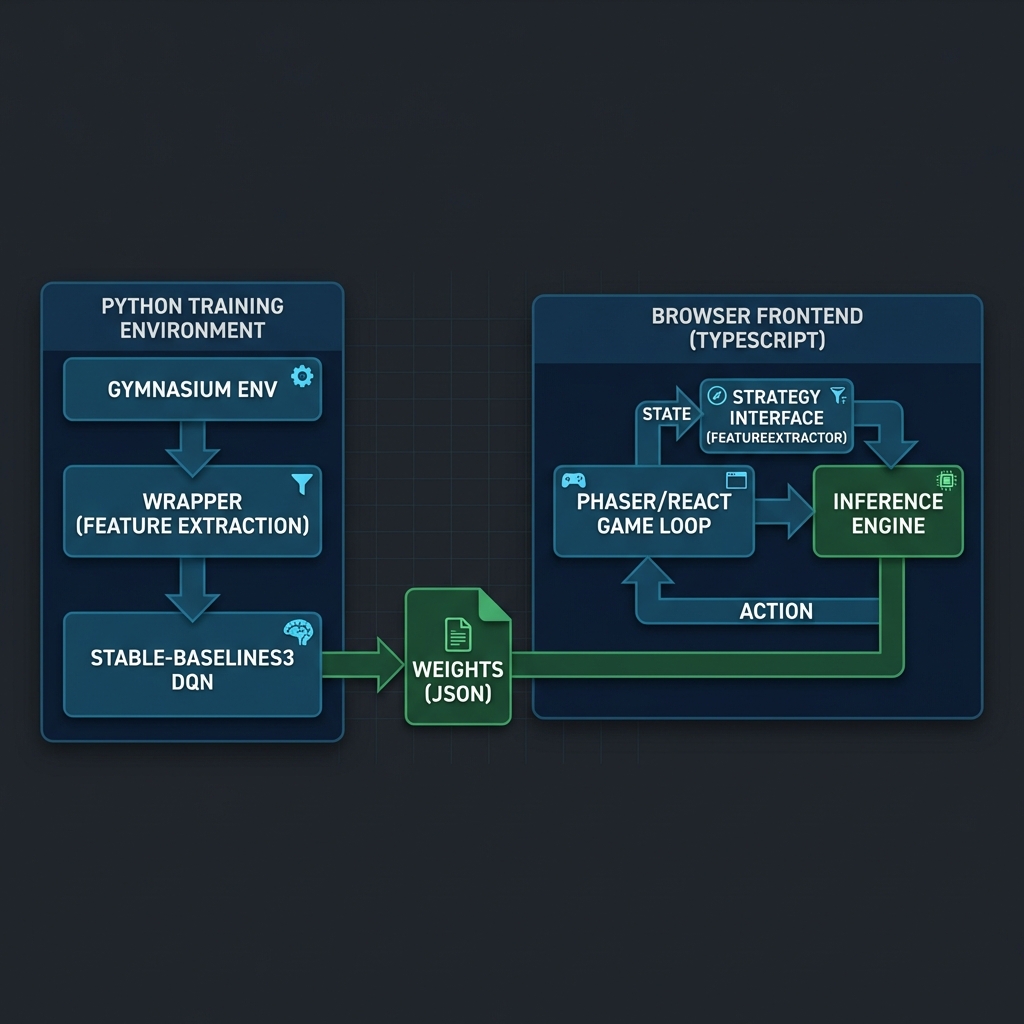
1. Python 訓練端 (Backend)
在這個階段,我們專注於訓練效率與算法實驗。
- 環境 (Environment): 使用
Gymnasium實作標準的 RL 介面。 - 包裝器 (Wrapper): 這是關鍵層。例如
LidarHungerWrapper負責將遊戲狀態轉換為 28 維的雷達數值。 - 模型 (Model): 使用
Stable-Baselines3的 DQN 算法進行訓練。
2. 資料交換層 (The Bridge)
我們不導出整個繁重的 TensorFlow/PyTorch 模型,而是僅導出 權重 (Weights)。
- 寫了一個
export_weights.py,將 PyTorch 模型的state_dict轉換為純 JSON 格式。 - 這個 JSON 檔非常小 (約 300KB),包含了神經網絡每一層的權重矩陣與偏差值。
3. TypeScript 推理端 (Frontend)
在瀏覽器端,我們實作了一個輕量級的推理引擎。
- 完全無依賴:不需要載入 TF.js 或 ONNX Runtime,純 TypeScript 矩陣運算。
- 零延遲:直接在 Client 端運行,無需網路請求。
核心設計:策略模式解決耦合
最大的挑戰在於:Python 端的特徵提取邏輯,必須與前端完全一致。
如果我們修改了 Python 的 LidarWrapper,增加了一個「距離」特徵,前端的程式碼通常也得大改。這就造成了緊密耦合。
為了解決這個問題,我們在前端採用了 策略模式 (Strategy Pattern),遵循 開放封閉原則 (Open-Closed Principle)。
即:對擴充開放,對修改封閉。
代碼實作
我們定義了一個 FeatureExtractor 介面:
export interface FeatureExtractor {
readonly name: string;
readonly featureDim: number;
extract(state: SnakeGameState): number[];
}然後實作不同的策略。
策略 A:舊版簡單視野 (Compact11)
export class Compact11Extractor implements FeatureExtractor {
readonly featureDim = 11;
extract(state) {
// 只看上下左右有無障礙物
// ...
return features; // 11維陣列
}
}策略 B:進階雷達視野 (LidarExtractor)
當我們想升級 AI 時,不需要修改 SnakeAI 核心,只需新增一個策略:
export class LidarExtractor implements FeatureExtractor {
readonly featureDim = 28;
extract(state) {
// 發射 8 道雷達光束偵測距離
// ...
return features; // 28維陣列
}
}依賴注入 (Dependency Injection)
最後,在 SnakeAI 類別中,我們透過建構子注入策略:
export class SnakeAI {
private extractor: FeatureExtractor;
constructor(config: { extractor: FeatureExtractor }) {
this.extractor = config.extractor;
}
predict(gameState) {
// 1. 委派給策略進行特徵提取
const features = this.extractor.extract(gameState);
// 2. 執行神經網絡推理
const qValues = this.forwardPass(features);
// 3. 返回最佳動作
return argmax(qValues);
}
}靈活切換
這讓我們能靈活地在不同模型間切換,甚至進行 A/B Testing:
// 載入舊版 AI
const legacyAI = new SnakeAI({
extractor: new Compact11Extractor()
});
await legacyAI.load('/models/snake_v1.json');
// 載入新版雷達 AI
const advancedAI = new SnakeAI({
extractor: new LidarExtractor()
});
await advancedAI.load('/models/snake_lidar.json');成果與優勢
- 開發速度快:Python 端改完訓練邏輯,只需跑一次
deploy.py,前端無縫更新。 - 效能極致:前端只需執行簡單的矩陣乘法,FPS 輕鬆達到 60+。
- 地圖泛化能力:由於我們的
LidarExtractor使用了「正規化距離 (Normalized Distance)」,訓練時在 10x10 地圖,部署到前端 32x32 地圖依然能完美運作,完全不需要重新訓練。
這套架構證明了:只要設計得當,機器學習也能以輕量、優雅的方式整合進現代 Web 應用中。
想親自體驗這隻 AI 嗎?歡迎到 贪吃蛇 AI 試玩!