傳統Q Learning玩21點
環境 Blackjack
import gymnasium as gym
env = gym.make('Blackjack-v1', natural=False, sab=False)
Q Table
玩家11點以下加牌都不會爆,所以Q Table把11點以下分一類,以及11~21點
莊家1~10點。以及A是否當11點用
import numpy as np
q_table = np.zeros(
(len(range(11,22)), len(range(10)), 2, env.action_space.n)
)
超參數
因為最後的reward隨機性很高(15點加牌 贏或輸都不一樣) 所以學習率(alpha)設小一點
epsilon = 0.3
alpha = 0.3
gamma = 0.95
選擇動作
from random import random
def get_action(state):
if random()<epsilon:
return env.action_space.sample()
return np.argmax(q_table[state])
訓練流程
tat_rewards_arr = []
tat_rewards = 0
N = 100000
for episode in range(N):
state, _ = env.reset()
state = compress_state(state)
done = False
while not done:
action = get_action(state)
next_state, reward, done, _, _ = env.step(action)
next_state = compress_state(next_state)
if done:
q_table[state+(action,)] += alpha * (reward - q_table[state+(action,)])
tat_rewards += reward
else:
q_table[state+(action,)] += alpha * (reward + gamma*np.max(q_table[next_state]) - q_table[state+(action,)])
state = next_state
if episode%1000==999:
epsilon *= 0.96
alpha *= 0.96
tat_rewards_arr.append(tat_rewards)
tat_rewards = 0
結果
import matplotlib.pyplot as plt
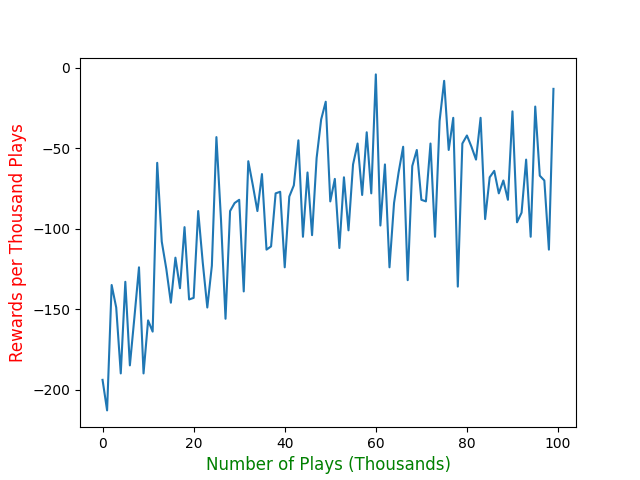
plt.plot(tat_rewards_arr)
plt.show()
每1000次遊玩,記錄一次總得分。大約十萬手牌之後逐漸收斂,但仍然無法穩定的擊敗莊家。
AI學出來的策略表
| 你的牌\莊家手牌 | A | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | T |
|---|---|---|---|---|---|---|---|---|---|---|
| 11 | H | H | H | H | H | H | H | H | H | H |
| 12 | H | S | H | H | H | S | H | H | H | H |
| 13 | H | S | H | S | S | S | H | H | H | H |
| 14 | H | H | S | S | S | H | H | H | H | H |
| 15 | H | S | H | S | S | S | H | H | H | H |
| 16 | H | S | S | H | S | S | H | H | S | H |
| 17 | H | S | S | S | S | S | S | S | S | S |
| 18 | S | S | S | S | S | S | S | S | S | S |
| 19 | S | S | S | S | S | S | S | S | S | S |
| 20 | S | S | S | S | S | S | S | S | S | S |
| 21 | S | S | S | S | S | S | S | S | S | S |